
When Google flags a page as 'Crawled - currently not indexed' in Search Console, it's not a technical error. It's a quality judgment.
Google's crawler, Googlebot, has successfully visited and analyzed your page. But it made a conscious decision not to add it to the search results. Think of it as a librarian reading a new book but deciding it's not quite ready for the public shelves.
It’s Google's polite way of saying, "I see you, but I'm not impressed yet."
This status leaves the page in a kind of digital purgatory—visible to Google, but completely invisible to people searching. Fixing this usually comes down to boosting the page's perceived value and authority by improving its content, strengthening internal links, and ensuring the technical setup is flawless.
Understanding Why Google Ignores Your Crawled Pages
At its core, Google's job is to give people the best possible answers. If your page offers nothing new, just rehashes information found elsewhere, or is simply too thin on substance, Google will likely pass on indexing it. It's a resource conservation thing.
This is especially common with:
- Thin Content: Pages with barely any text or useful information.
- Duplicate Content: Pages that are almost identical to others on your site or across the web.
- Low-Value Pages: Things like tag pages, empty category pages, or internal search results that don't offer unique value.
Lately, user engagement has become a massive factor. We saw this firsthand during the "Google Indexing Purge Update" that started around May 26th, 2025. On some sites we monitor, over 25% of URLs were de-indexed. The common thread? A serious lack of user interaction. Pages with minimal clicks and impressions were cut.
Beyond the content itself, technical and structural problems can make Google hesitate. A weak internal linking structure, for example, can orphan a page. This sends a signal to Google that even you don't think the page is important enough to link to from other parts of your site.
A page's journey from crawled to indexed is a clear signal of its perceived importance. If it gets stuck, it’s time for a hard look at whether the page truly deserves a spot in the search results.
This is a different beast from issues like soft 404s, where a page might be gone but the server sends the wrong signal. Here, the page exists—its value is just in question.
To get a handle on this, let's look at the most common culprits and where to start your investigation.
Common Causes and Initial Checks
This table breaks down the usual suspects and gives you a clear first step for diagnosing the problem.
| Potential Cause | Primary Symptom | First Diagnostic Step |
|---|---|---|
| Thin or Low-Quality Content | The page offers little unique information, has a high bounce rate, or very short time-on-page. | Manually review the page. Does it fully answer a user's question? Is it better than the top-ranking pages? |
| Duplicate Content Issues | Page content is identical or nearly identical to another page on your site or another website. | Use the URL Inspection tool in GSC to check the "Google-selected canonical." Paste a paragraph into Google to see if it appears elsewhere. |
| Weak Internal Linking | The page has few or no internal links pointing to it, making it seem unimportant. | In GSC, go to Links > Internal links and check the link count for the affected URL. Also, perform a site search (site:yourdomain.com "keyword") to see how it's linked internally. |
| Poor User Engagement | The page gets very few clicks from search results or visitors leave almost immediately. | Check GSC's Performance report for the URL. Are clicks and impressions near zero? Review Google Analytics for high bounce rates or low engagement time. |
This checklist isn't exhaustive, but it covers the vast majority of cases we see. Starting here will help you quickly narrow down the root cause before you start making changes.
When a page gets flagged as "Crawled - currently not indexed," it's tempting to jump straight to complex theories about content quality or site authority. But honestly, that’s usually not the right place to start.
The best approach is a methodical one, starting with the simple stuff first. Your command center for this whole operation is the URL Inspection tool in Google Search Console. Think of it as your direct line to Google—it tells you exactly how they see a specific page, cutting through all the guesswork.
Before you even think about rewriting content, you have to rule out the basic technical roadblocks. It’s like checking if a lamp is plugged in before you start rewiring the house. The URL Inspection tool gives you clear "yes" or "no" answers to the most fundamental indexing questions.
First Things First: The URL Inspection Tool
Grab the URL that’s giving you trouble and paste it into the search bar at the top of Google Search Console. This pulls a report on that page’s status straight from Google's index. This is the single most important first step you can take, and it only takes a few seconds.
You’re looking for three key pieces of information under the Coverage section:
- Crawl allowed? This tells you if your robots.txt file is blocking Googlebot. A "No" here is a massive red flag and, nine times out of ten, the root of your problem.
- Page fetch: This confirms if Google could actually retrieve the page. A "Failed" status points to server errors, timeouts, or other loading issues.
- Indexing allowed? This checks for a
noindextag in your HTML or HTTP headers. If this says "No," you’ve found a direct order telling Google to stay away.
If any of these checks fail, your path is crystal clear. You have a technical directive blocking indexing that has absolutely nothing to do with how good your content is. Fixing that noindex tag or the robots.txt rule needs to be your top priority.
This screenshot shows what this data looks like, reflecting the kind of report the URL Inspection tool provides.
You can see the key data points like crawl status and indexability, confirming whether the technical permissions are even in place for Google to process the page.
Next, Check Your Canonical Signals
Once you've confirmed all the basic technical checks are green, your next stop within that same URL Inspection report is the Google-selected canonical. This is the URL Google has decided is the real version of the page.
Sometimes, Google will crawl your page just fine but decide another page on your site is a better, more authoritative version, choosing to index that one instead.
If the Google-selected canonical URL is different from the page you are inspecting, you have a canonicalization issue. Google has crawled your page but has decided to consolidate its signals with another URL.
This isn't always a mistake—it might be exactly what you intended. For instance, a URL with tracking parameters (?utm_source=newsletter) should absolutely canonicalize back to the main page. But if Google is choosing the wrong canonical, it’s a sign that you need to strengthen your own signals using the rel="canonical" link element on the page.
Get Real-Time Answers with a Live Test
The data in the main URL Inspection report is based on Google's last crawl, which could have been days ago. If you've just pushed a fix, that report won't reflect it yet. That's where the "Test Live URL" button becomes your best friend.
This feature sends Googlebot to your page in real-time to see how it looks right now. It's the perfect way to verify a fix. For example, if you just removed a pesky noindex tag, the Live Test will immediately confirm that "Indexing allowed?" now returns a "Yes."
Use the Live Test to confirm:
- Accessibility: Can Googlebot even reach the page?
- Rendered HTML: What does Google see after all your JavaScript has finished running?
- Mobile Usability: Is the page actually usable on a phone?
Once your live test comes back with all green lights—crawl allowed, page fetch successful, and indexing allowed—you can confidently rule out the most common technical blockers. Only then does it make sense to start digging into deeper issues like content quality and internal linking.
Solving Technical SEO Roadblocks to Indexing
If your diagnostic checklist keeps pointing away from content quality, it’s time to put on your technical SEO hat. More often than not, the real reason a page is stuck in indexing limbo has nothing to do with the words on the page—it’s all about the invisible signals and structures supporting it. These technical gremlins can stop Googlebot cold.
A lot of these issues are baked into how a website was built in the first place. Foundational problems can create ongoing indexing headaches, which is why implementing robust software engineering best practices from the start is so critical. Getting the code and server configuration right from day one prevents these kinds of problems from ever cropping up.
This decision tree gives you a visual path for figuring out whether you're dealing with a technical snag or a quality-based indexing problem.
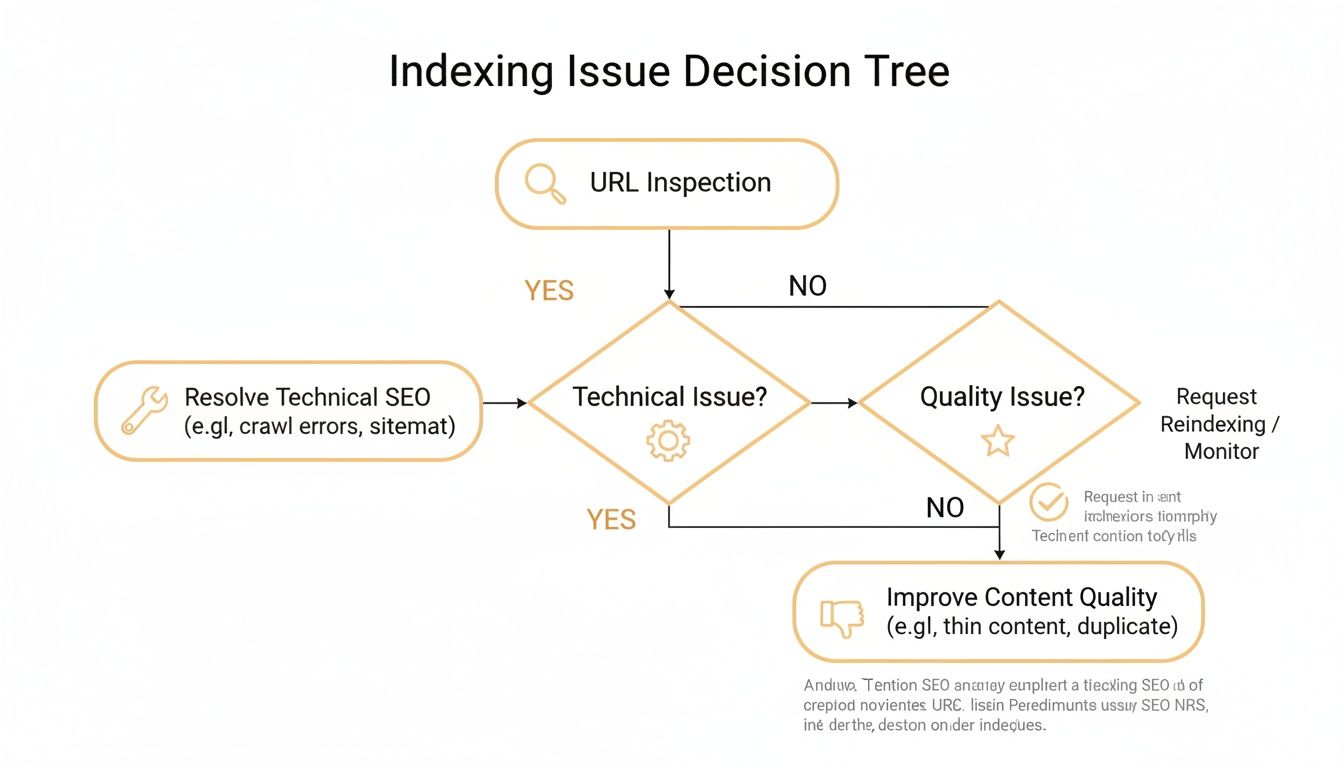
As the flowchart shows, your first move should always be the URL Inspection tool. It's the fastest way to branch your investigation toward either technical fixes or content improvements.
Taming Your XML Sitemap
Think of your XML sitemap as the official map you hand-deliver to Google. A clean, accurate map leads Googlebot straight to your most valuable pages. A messy one, on the other hand, is filled with dead ends, detours, and outdated info that just wastes Google’s time and crawl budget.
Your sitemap needs to be a pristine list of your best, indexable URLs. It should never contain:
- Redirected URLs (3xx): Sending Google to a page that just points somewhere else is plain inefficient.
- Client or Server Error URLs (4xx/5xx): Why would you ever guide a crawler to a broken page?
- Non-Canonical URLs: Every single URL in your sitemap should be the primary version you want indexed.
- Noindexed Pages: This is a completely contradictory signal—asking Google to crawl a page you’ve specifically told it not to index.
Auditing your sitemap regularly to remove this junk is non-negotiable. It ensures you’re giving Googlebot a clean, efficient path, which seriously increases the odds that your important pages get crawled and considered for indexing.
Confronting Server and Speed Issues
Google operates on a pretty tight "crawl budget," meaning it only allocates a certain amount of resources to crawl any given site. If your server is slow or unreliable, you’re basically making it harder for Google to do its job. A sluggish server response can cause Googlebot to give up before it even gets to your page's content.
Intermittent 5xx server errors are especially damaging. If Googlebot hits an error when it tries to visit, it might not come back for a while. If that keeps happening, Google could decide to de-prioritize crawling that page altogether. Performance is directly tied to crawling and indexing; you can learn more about this relationship by understanding what Core Web Vitals are and how they impact both user and bot experiences.
Decoding JavaScript Rendering Problems
Modern websites lean heavily on JavaScript to display content, but this can create a huge roadblock for search engines. If your critical content is only visible after JavaScript runs, Google has to take an extra step to render the page before it can “see” what’s actually there.
Sometimes, that rendering process fails. Use the "Test Live URL" feature in the URL Inspection tool and check out the rendered HTML. Does it match what a user sees in their browser? If your main content, headings, or internal links are missing from the code Google sees, you have a JavaScript SEO problem that is almost certainly blocking indexing.
I’ve seen this happen a lot with blogs where articles are loaded dynamically. Google's initial HTML crawl finds an empty content area, assumes the page has no value, and moves on. It never waits around for the JavaScript to populate the text, so the page is never indexed.
The reality is, technical SEO glitches are a massive driver of this issue, standing as the second most common trigger for the 'crawled - currently not indexed' status. During some indexing events in May 2025, we saw this status spike to over 200,000 pages on certain sites. The cause was strongly correlated with server instability, messy sitemaps, and JavaScript rendering failures. You can find more tips on
and applying the right fixes.Boosting Content Quality to Earn Your Index Spot
So, you've run through all the technical checks and everything looks clean, but some of your pages are still stuck in indexing limbo. This is usually the point where the conversation pivots from code to content. When this happens, it means Google has successfully crawled your page and, for whatever reason, decided it just isn't valuable enough to show to its users.
This is where you have to take off your site owner hat and start thinking like a search engine.
The big question becomes: does this page actually deserve to be in the index? More often than not, pages flagged with "crawled - currently not indexed" are what we'd call thin. They might lack unique insights, rehash what's already out there, or just completely miss the mark on what the user was actually looking for. It's not about word count; it’s about providing genuine, substantive value that isn't already plastered all over the internet.
From Thin Content to Authoritative Resource
"Thin content" is the most common culprit I see. And let me be clear: this doesn't just mean a low word count. I've seen 3,000-word articles that are completely thin because they just rephrase information from the top three search results. Real value comes from bringing something new to the table.
To beef up a struggling page, think about adding elements that provide unique value nobody else has:
- Original Data: Got survey results? An internal case study? Any kind of unique research? Put it in there.
- Expert Commentary: Feature quotes or fresh insights from actual subject matter experts in your field.
- Unique Visuals: Instead of stock photos, create custom infographics, charts, or diagrams that simplify complex topics.
- Actionable Checklists: Give readers practical, step-by-step lists that help them apply what they've just learned.
Ultimately, earning your spot in the index comes down to quality. If you really want to build pages Google will prioritize, you need to know how to optimize content for SEO. The goal isn't just to publish a page; it's to transform it from a simple summary into an indispensable resource.
Here's a good gut check: If your page vanished from the internet tomorrow, would anyone actually notice or miss it? If the answer is no, it’s a prime candidate for a serious content overhaul. Google wants to index pages that add something new to the conversation.
This isn't just a theory; it's become a huge factor recently. We've seen firsthand that low-quality content is a massive driver for this indexing status. During a significant indexing purge that began in late May 2025, about 25% of websites we monitored saw a 3x to 4x increase in pages marked "crawled - currently not indexed." This particularly hit pages with zero clicks, like sparse blog posts and thin category pages.
Master Strategic Internal Linking
Even the world's best content can get ignored if it's an "orphan page"—a page with few or no internal links pointing to it. A weak internal linking structure basically tells Google that you don't even think the page is very important. If you don't link to it, why should they bother ranking it?
The fix is to build bridges from your site's "power pages" to your unindexed ones. Your power pages are your high-traffic, high-authority articles, and core service pages. A single link from one of these acts like a vote of confidence, passing authority and screaming to Google, "Hey, this page over here matters!"
A quick way to find these opportunities is with a simple Google search:
site:yourdomain.com "keyword of unindexed page"
This command will show you every single page on your site that already mentions the topic of your unindexed page. These are perfect, natural spots to add a new internal link. This is one of the quickest and most effective fixes I know for "crawled - currently not indexed." It's also a fundamental part of all good SEO content writing tips.
When to Enrich vs. When to Prune
Now for some tough love: not every page is worth saving. Sometimes, the most strategic move you can make is to remove or redirect low-value content. This is called content pruning, and it consolidates your site's authority onto fewer, higher-quality pages. Deciding whether to improve a page or just get rid of it comes down to its potential value.
This table can help you make the call.
Content Enrichment vs. Strategic Pruning
| Criteria | When to Enrich the Content | When to Prune or Redirect |
|---|---|---|
| Topic Relevance | The topic is core to your business and has real search potential. | The topic is outdated, irrelevant, or no longer aligned with your goals. |
| Existing Traffic | The page gets some traffic or has backlinks, but engagement is low. | The page has zero traffic, no backlinks, and no engagement signals at all. |
| User Intent | The page aligns with a clear user search intent but isn't satisfying it fully. | The page targets a keyword with no clear intent or is redundant with another page. |
| Uniqueness | The page has the potential to be a unique, valuable resource with more work. | The content is nearly identical to another page on your site (duplicate content). |
By honestly assessing each page against these criteria, you can make a smart, strategic decision that strengthens your site's overall quality. This focused approach ensures your efforts are spent on pages that can actually earn their spot in Google's index, rather than wasting time on pages that will never make the cut.
Validating Fixes and Preventing Future Issues
Getting a page indexed is a good start, but the real win is keeping it that way. You don't want your other pages falling into the same digital limbo down the road. After you've put in the work—whether it’s beefing up content or squashing a technical bug—the job isn't over. You need to confirm your changes actually worked and set up a system to stay ahead of future problems.
This is where you shift from being reactive to proactive. Think of Google Search Console not just as a tool for diagnosing problems, but for preventing them in the first place.
Using Validate Fix in Google Search Console
Once you’re confident you've addressed the issues for a group of URLs, it's time to let Google know. Head back to the "Crawled - currently not indexed" report in GSC. You’ll see a big "Validate Fix" button waiting for you.
Clicking this button is your way of telling Google, "Hey, I think I've sorted this out. Can you take another look?" This kicks off a new monitoring process for that specific group of pages.
This validation process doesn’t happen overnight. It unfolds in a few stages:
- Starts: Google gets your request and adds the URLs to its re-crawling queue. This can take a few days just to get going.
- Pending: Google is actively visiting your pages to see if the problems are gone. This is the longest part and can easily last for several weeks, so patience is key.
- Passed or Failed: Once the check is complete, you'll get the verdict. "Passed" means your pages are out of the excluded category—they're either indexed or have another valid status. "Failed" means the original issue is still there.
Don't panic if validation fails. It’s not a penalty. It’s just Google's way of saying the root cause wasn't fixed, and it's time to go back to the drawing board for those specific pages.
Building a Proactive Monitoring Routine
Honestly, the best way to deal with the "Crawled - currently not indexed" issue is to stop it from happening in the first place. A simple, consistent monitoring routine can help you spot trouble long before it snowballs.
Try to build this into your weekly or bi-weekly workflow:
- Check the Page Indexing Report: Make it a habit to glance at the "Why pages aren’t indexed" section in GSC. If you see a sudden jump in "Crawled - currently not indexed" pages, it’s a huge red flag. It often means a recent site update went wrong or Google's quality standards have shifted.
- Scan Your Crawl Stats: Navigate to Settings > Crawl stats. You're looking for anything out of the ordinary here. A sharp drop in the number of pages crawled per day could point to server trouble. A spike in the time it takes to download a page might signal performance issues. Both are early warning signs of indexing problems.
- Dig into Server Logs: If you're comfortable getting more technical, your server logs are a goldmine. They show you every single interaction Googlebot has with your site. You can spot things like Google wasting its crawl budget on useless URL parameters or repeatedly hitting errors in a specific directory.
By keeping an eye on these key reports, you can find and fix indexing roadblocks before they start hurting your site's visibility. It’s this proactive mindset that ensures your best content actually gets seen by Google and your audience.
Common Questions About Indexing Problems
Even after digging into diagnostics, a few common questions about that frustrating "Crawled - currently not indexed" status always come up. Let's tackle them head-on to clear up any confusion and set some realistic expectations.
How Long Does Indexing Take After I Fix Something?
This is the million-dollar question, and I wish I had a better answer than "it depends." Once you've fixed an issue and hit "Validate Fix" in Search Console, you're officially on Google's time, not yours. How fast your page gets re-crawled and indexed really comes down to your site's overall authority and how often Googlebot swings by.
If you're running a high-authority site that Google crawls daily, you might see a change in just a few days. But for a smaller or newer site that Google doesn't visit as often, it could honestly take several weeks.
A little patience goes a long way in SEO. The validation process in GSC can last up to a month. As long as you've confirmed your fix using the "Test Live URL" tool, you can be confident that you’ve done your part on the technical side.
The key is to manage your expectations. Don't check GSC every hour expecting an overnight miracle. Monitor the validation, but focus your energy elsewhere while Google does its thing.
Can I Make Google Index My Page Faster?
The short answer is no. You can't force Google to do anything. The best you can do is give it a strong nudge using the "Request Indexing" button in the URL Inspection tool. Think of it less like a command and more like raising your hand in a packed classroom to get the teacher's attention.
Submitting your URL pushes it into a priority crawl queue, but here's the catch: if the underlying reason for non-indexing—like thin content or a lack of internal links—is still there, it won't matter. Google will just re-crawl it, see the same old problems, and decide not to index it all over again.
This tool is most powerful after you’ve made significant improvements. Once you’ve genuinely beefed up a page's value, requesting indexing is the perfect way to signal that it’s ready for another look.
Is "Crawled - Currently Not Indexed" Always a Bad Thing?
Surprisingly, no. Sometimes, seeing this status is actually a good sign. It means Google is correctly identifying low-value pages and choosing not to waste resources on them, which saves your crawl budget for the content that really matters.
Here are a few scenarios where this status is perfectly fine:
- Filtered Search Results: Think of pages created when a user applies filters on an e-commerce site (e.g.,
.../shoes?color=blue&size=10). These URLs offer little unique value and shouldn't be clogging up the index. - Low-Value Tag Pages: If a tag is only used on one or two blog posts, its archive page is essentially duplicate content. It's better for Google to just ignore it.
- RSS Feed URLs: These are built for feed readers, not for people to find in search results. It’s perfectly normal for them to remain unindexed.
The real skill is learning to tell the difference between a problem that needs fixing and a strategic non-indexing that actually helps your site's SEO. If the page in question is a critical service page or a cornerstone blog post, you've got a problem. If it's a paginated URL from an archive from five years ago, you can probably let it go.
At Up North Media, we know that navigating these SEO complexities can be a real headache. If you're struggling to get your most important pages indexed and need a data-driven strategy to improve your visibility, our team is here to help. Learn more about our SEO marketing services and schedule a free consultation today.