
If you tried to open a Railway dashboard this evening and hit a wall of errors, you were not alone. Starting around 10:29 PM UTC on May 19, Railway, the developer-friendly platform that hosts backends, databases, and APIs for thousands of companies, went into a full major outage. Dashboards stopped loading. Logins failed. Live apps started returning "no healthy upstream" errors and 404s on domains that had been up for years.
This one hits close to home for us. We run backend services for client projects on Railway, so when it goes down, we feel it the same way our clients and their customers do. That gives us a front-row seat and a pretty strong opinion about what this outage actually teaches.
Here is the short version, the real cause, and what we are telling clients to do about it.
What actually happened
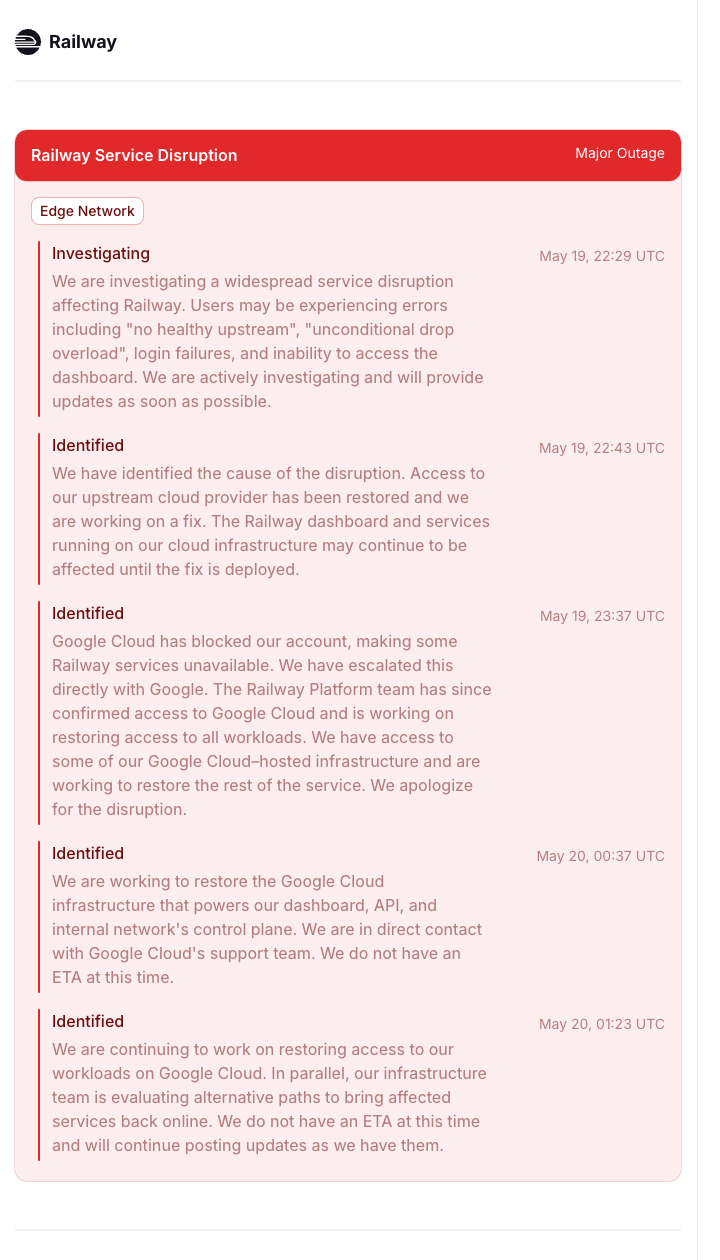
The timeline moved fast. Around 10:29 PM UTC, Railway's status page flipped to a major service disruption. Within minutes, the company confirmed the dashboard was unavailable and that all running services on its cloud infrastructure were down. Workloads on Railway Metal, the company's own bare-metal infrastructure, kept running. Everything on the cloud side did not.
About an hour later, at roughly 11:37 PM UTC, Railway published the root cause: Google Cloud had blocked its account. The team said it had escalated directly with Google, had since regained access to some of its Google Cloud infrastructure, and was working to restore the rest. As of this writing, partial access was back but there was no ETA on full recovery. To Railway's credit, the updates were frequent, plain-spoken, and apologetic.
| Time (UTC) | Update | Why it mattered |
|---|---|---|
| May 19, 22:29 | Railway opened a major outage for Edge Network errors, dashboard access failures, and login failures. | This was the first public sign that the issue was broader than a single app or region. |
| May 19, 22:43 | Railway said access to its upstream cloud provider had been restored and a fix was underway. | The provider dependency was already visible before Google Cloud was named directly. |
| May 19, 23:37 | Railway said Google Cloud had blocked its account. | That turned the incident from normal provider downtime into an account-level infrastructure failure. |
| May 20, 00:37 | Railway said it was restoring the Google Cloud infrastructure powering its dashboard, API, and internal network control plane. | The control plane impact explains why teams lost more than app uptime. |
| May 20, 01:23 | Railway said it was still restoring Google Cloud workloads and evaluating alternate recovery paths. | At that point, the outage had become a resilience and failover problem, not just a status-page problem. |
Official posts during the outage
Railway and team members also posted public updates on X while the incident was unfolding. These are useful because they show the message moving from "some services are unavailable" to "Google Cloud blocked our account" in real time.
Google Cloud has blocked our account, making some Railway services unavailable. We have escalated this directly with Google. The Railway Platform team has since confirmed access to Google Cloud and is working on restoring access to all workloads.
— Railway (@Railway) May 19, 2026
We have access to some of our… https://t.co/7DUr7nVFz1
It appears Google Cloud has blocked our account, and so some services are unavailable
— Jake (@JustJake) May 19, 2026
We’ve escalated this to Google and will keep people posted. Deepest apologies. https://t.co/xO2DsFxsRJ
We are still working with Google on getting this sorted.
— Noah (@itsnoahd) May 20, 2026
Here for any questions. Ask away https://t.co/8JauYY4NwR
The root cause is the wild part
Railway is a cloud provider. But Railway runs a large chunk of its own platform, including the dashboard, the API, the control plane, and many customer workloads, on top of Google Cloud. So when Google blocked Railway's account, it did not just slow things down. It knocked out the layer Railway uses to run everything else.
There is still no public explanation from Google or Railway on why the account was blocked. Blocks like this usually trace back to a billing flag, automated abuse detection, or a compliance review, but nobody has confirmed which.
The detail worth sitting with is this: a company whose entire business is hosting your infrastructure got locked out of the infrastructure it rents. That is the cloud equivalent of a landlord getting locked out of his own building.
Who got hit, and what it cost
The blast radius was wide. Hundreds to thousands of companies were affected: SaaS products, e-commerce backends, internal tools, AI apps, crypto and DeFi services, and live client demos all went dark at once. Teams reported lost revenue, support queues filling up, and at least one canceled sales call with a major prospect. Anything on Railway Metal stayed online. Anything on the Google Cloud side did not.
For a lot of teams, the part that stung most was not the downtime itself. It was realizing mid-outage that they had no backup, no failover, and no way to even reach their own data while the dashboard was offline.
This is not Railway's first Google Cloud headache
A bit of context matters here. Back in June 2025, a major Google Cloud outage sent a wave of customers rushing onto Railway, to the point that Railway had to throttle and pause builds on its lower tiers to protect paying customers. That episode is exactly what pushed Railway to lean harder into Railway Metal and to talk publicly about reducing its dependence on Google Cloud.
The Metal push clearly helped, since those workloads survived tonight. But enough of the platform still leaned on Google Cloud that a single account-level block took the whole control plane down anyway. Diversification that is still in progress is not the same as diversification that is finished.
The real lesson is not "Railway bad"
Railway handled the communication well: real-time updates, a clear root-cause statement, and direct escalation to Google. The lesson here is bigger than any one platform.
But Railway does deserve criticism here. If customers trust you with production infrastructure, your dashboard, API, and internal network control plane cannot depend so heavily on one upstream account that losing access leaves you waiting on that same provider to restore your ability to recover. Good incident communication matters, but it is not a substitute for a tested backup plan.
Every layer of your stack has a dependency you do not control. Your host depends on a larger cloud. That cloud depends on power, networking, and its own automated systems. Any one of those can fail or, as we just watched, simply decide to cut someone off. Single-provider risk is not a Railway problem. It is a structural reality of how modern apps get built.
The companies that rode this out calmly were not the ones on a flawless platform. They were the ones who had a plan for when a platform fails.
What we are telling clients to do
You do not need to tear out your stack over one bad night. You do need a few basics in place so the next outage is an annoyance instead of an emergency.
| Resilience Move | Effort | Payoff |
|---|---|---|
| Automated off-platform database backups, run daily and stored somewhere other than your host | Low | Huge. You can rebuild anywhere if your provider disappears. |
| Infrastructure as code, with Docker and config living in your repo | Medium | You can redeploy to a new provider in hours, not weeks. |
| A documented failover provider, chosen before you need it | Low to Medium | Turns a panic into a checklist. |
| Uptime monitoring and a status page with real alerts | Low | You hear about outages from a tool, not from an angry customer. |
| Keeping core logic free of provider-specific lock-in | Medium | Your critical code stays portable across hosts. |
None of these are exotic. The most valuable one, off-platform backups you actually control, is also the cheapest. When we architect a client application, we deliberately keep the core business logic, things like the payment flow and the main application engine, independent of any single host's proprietary APIs. That way a migration is a connection-string change, not a rewrite.
Key Takeaways
- An outage is a "when," not an "if." Even mature platforms go down. Plan for it instead of hoping against it.
- Own your backups. If your data only lives where your provider keeps it, you do not really have a backup.
- Keep core logic portable. The less your critical code leans on one vendor's special features, the easier it is to move.
- Judge a vendor by its recovery, not just its uptime. Railway's transparency tonight counts for something. How a provider communicates in a crisis tells you a lot about whether you want to keep building on it.
Worried your app has a single point of failure you have never stress-tested? At Up North Media, we build web applications with portability and resilience baked in from day one, so a bad night for your host does not have to be a bad night for your business. Get in touch for a free architecture review.